Was das Framework leistet
Sechs Perspektiven statt Einzellösung, frühe Risikoerkennung und Governance-by-Design in einer Sequenz. Auditierbar, erweiterbar, Enterprise-tauglich. Lokaler KI-Betrieb hält Daten im Unternehmen.
Simulate. Understand. Decide.
Ein eigenständiges Framework zur Simulation von Entscheidungs- und Prozessdynamiken in IT- und BPM-Vorhaben. Mehrere spezialisierte Rollen analysieren denselben Change Request gleichzeitig und parallel. Damit werden typische Probleme (widersprüchliche Entscheidungen, späte Konflikte, übersehene Risiken) sichtbar, bevor ein Projekt überhaupt produktiv startet. Diese Seite zeigt das aktuelle Reifebild eines lauffähigen Prototyps, die konzeptuelle Architektur sowie die Skalierungs-Roadmap vom lokalen Mini-PC über einen GPU-Cloud-Pod bis zur Anbindung produktiver Online-Modelle.
 🔍 Vergrössern
🔍 Vergrössern
Anforderungen werden in der Regel schriftlich, strukturiert und nach Priorität geordnet eingereicht. Der Empfänger hängt vom Kontext ab. Im Arbeitsalltag sind es meist interne IT-Teams, das Produktmanagement oder die Projektleitung, abgewickelt über Ticketsysteme wie Jira, Azure DevOps, ClickUp, ServiceNow oder Asana.
Anforderungen für Prozessanpassungen, Change Requests, Bug-Fixes oder neue Initiativen sind in der Praxis fachlich häufig schlecht beschrieben. Implizites Wissen wird vorausgesetzt, die Schnittstellen zwischen Fachbereich und IT bleiben unklar, und Anforderungen werden oft als Lösung statt als Problem formuliert.
In agiler Softwareentwicklung wird zugunsten knapper User Stories häufig auf ausführliche Spezifikationen verzichtet. Ohne saubere Akzeptanzkriterien und ohne fachliche Prozessmodelle wie BPMN entstehen Missverständnisse. Beschrieben wird meist nur der goldene Weg, also der Idealfall. Seltene Ausnahmen, Fehlerbehandlungen und Folgeprozesse bleiben ausgeblendet, was zu Lücken in der späteren Systemanpassung führt.
Den Beteiligten fehlt zudem oft eine gemeinsame Sprache. Fachbereiche denken in Business-Begriffen, während die IT logische und systemische Regeln benötigt. Wo das Bindeglied fehlt, typischerweise ein Business Analyst, bleiben die Beschreibungen vage.
Workshops, Reviews und Backlog Refinements sind die etablierten Praktiken, um Anforderungen nach der ersten Einreichung zu verbessern. Eine klare Definition of Ready hilft, das Niveau dieser Formate zu sichern. Diese Praktiken sind notwendig und wertvoll, setzen aber alle nach der Einreichung an, also zu einem Zeitpunkt, an dem die Anforderung bereits in Umlauf gebracht wurde. Vertagungen, Nachschärfungen und Eskalationen sind die häufigen Folgen einer solchen rein reaktiven Qualitätskontrolle.
Das Role-Based Decision & Process Simulation Framework setzt davor an. Durch die iterative Konsultation virtueller Rollen entsteht ein konsolidierter Entscheidungsreport mit Governance-Status, Rollenkonflikten, Risiko-Klassifizierung, Pattern-Empfehlungen, Architektur-Skizze und nächsten Schritten. Dadurch gelangt die Anforderung in einem deutlich tragfähigeren Zustand ins Backlog Refinement. Auch dort, wo eine Anforderung bereits Lösungsansätze enthält, die im Unternehmen akzeptiert sind, lassen sich diese gegen die fachliche und technische Sicht der relevanten Rollen prüfen.
Die Methode ist aus rund zwanzig Jahren Praxis in Prozess- und Requirements Engineering in agilen Software-Entwicklungs-Kontexten entstanden, mit Schwerpunkten in Banking, Versicherung und Medien. Konzeptioneller Bezugspunkt ist die Schwarmintelligenz-Idee aus offenen Multi-Agent-Engines wie MiroFish. Die Implementierung, die Rollen-Spezifikationen, die Konsolidierungs-Logik und die domänenbezogene Anwendung auf Enterprise-Entscheidungsvorbereitung sind eigene Arbeit.
Die hier gezeigte Schicht ist eine Präsentations- und Demonstrations-Schicht. Sie ist bewusst eingegrenzt durch die Lesbarkeit für ein gemischtes Publikum und durch die Möglichkeiten der lokal betriebenen Ollama-LLM-Runtime auf dem NAB9-Mini-PC. Höhere Ausbaustufen wie Ressourcen- und Kapazitäts-Bewertung oder Cloud- und GPU-basierte Parallelisierung sind in der Roadmap angelegt, aber nicht Teil dieser Schicht. Die weiter unten beschriebenen Anwendungsschichten sind Beispiele aus einem grösseren Spektrum, abhängig von der Entwicklungsstufe des jeweiligen Unternehmens.
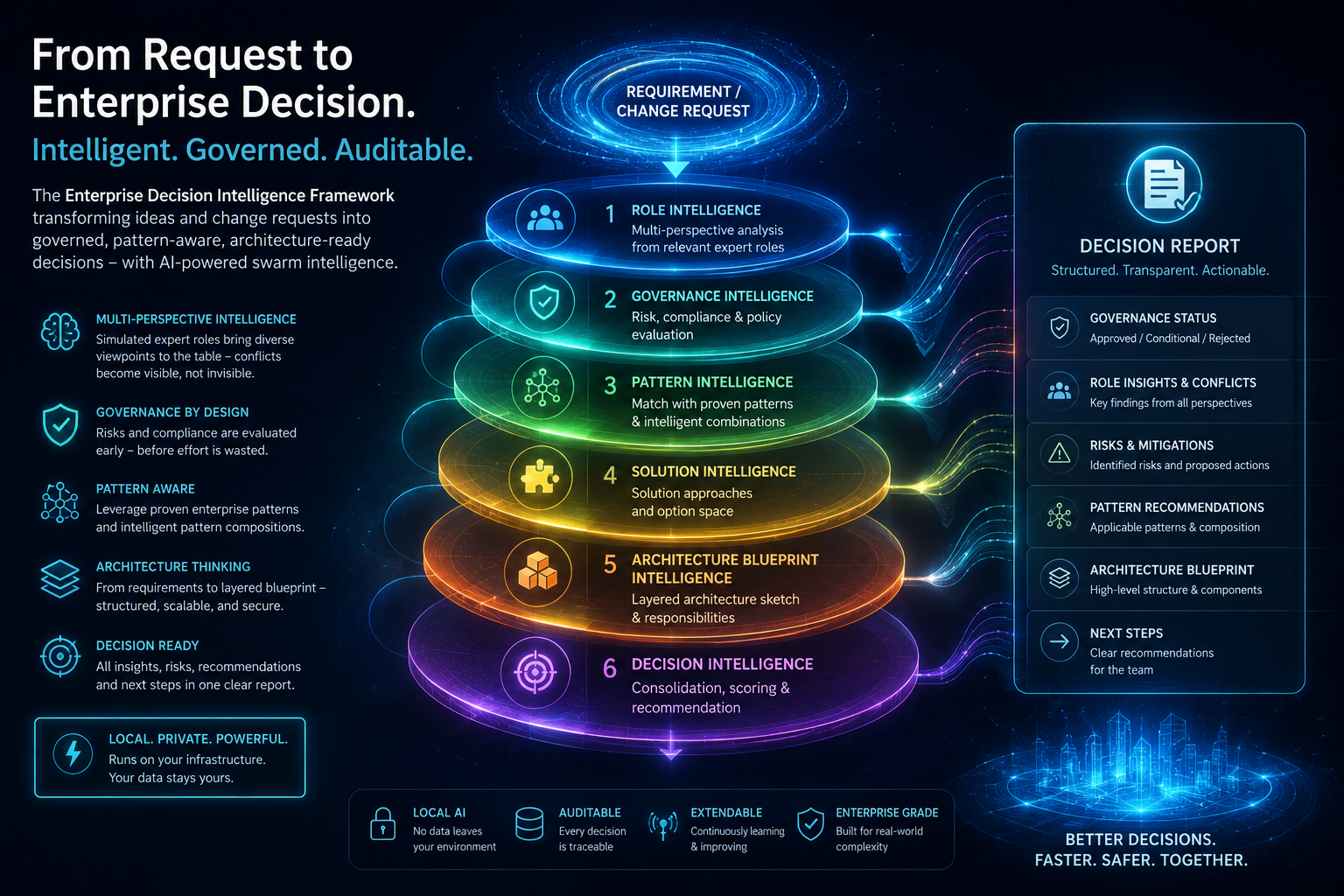
Das Framework arbeitet in mehreren aufeinander aufbauenden Intelligence-Schichten. Eine Anforderung durchläuft sie als Sequenz, am Ende steht ein konsolidierter Entscheidungsreport.
Die Kette verläuft von Requirements oder Change Request über Role Intelligence, Governance Intelligence, Pattern Intelligence, Solution Intelligence, Architecture Blueprint Intelligence und Decision Intelligence zum Entscheidungsreport. Jede Schicht baut auf den Ergebnissen der vorhergehenden auf.
 🔍 Vergrössern
🔍 Vergrössern
Die folgenden sechs Karten erläutern jede Schicht im Detail. Farbe und Nummer der Karten entsprechen der jeweiligen Schicht in der Grafik oberhalb.
Mehrere spezialisierte Rollen erheben parallel ihre Sichten auf den Antrag. Konflikte zwischen Rollen werden sichtbar gemacht, nicht aufgelöst.
Risiken werden früh erkannt und klassifiziert. Kritische Anträge können gestoppt werden, bevor sie weitere Ressourcen binden. Governance-by-Design.
Die Anforderung wird gegen wiederkehrende Lösungs- und Strukturmuster geprüft. Passende Muster und sinnvolle Kombinationen werden benannt.
Aus Rollen-Perspektiven und Mustern entsteht ein Lösungsraum mit fachlichen Optionen, ohne Festlegung auf eine konkrete technische Umsetzung.
Eine fachlich-technische Zielstruktur mit klaren Verantwortungsgrenzen entsteht. Frontend, API, Sicherheit, Audit und Speicher werden sauber getrennt.
Alle Vorschichten werden zu einer Entscheidungsgrundlage verdichtet. Empfehlung, Risiko-Klassifizierung und Handlungsoptionen kommen zusammen.
Aus dieser Sequenz entsteht der Entscheidungsreport mit sechs strukturierten Komponenten. Die Farbe einer Komponente verweist auf die Quell-Schicht in der Grafik.
Freigegeben, mit Auflagen oder Abgelehnt, mit Begründung.
Kernerkenntnisse und Spannungsfelder aus allen Rollen-Sichten.
Identifizierte Risiken mit vorgeschlagenen Massnahmen.
Anwendbare Muster und sinnvolle Kombinationen.
High-Level-Struktur und Verantwortungsbereiche.
Klare Handlungsempfehlungen für das Umsetzungsteam.
Funktionsweise · Reflexion
Was das Framework leistet
Sechs Perspektiven statt Einzellösung, frühe Risikoerkennung und Governance-by-Design in einer Sequenz. Auditierbar, erweiterbar, Enterprise-tauglich. Lokaler KI-Betrieb hält Daten im Unternehmen.
Roadmap
Target Architecture Intelligence als spätere Schicht entwickelt die heutige Blueprint-Schicht zur mittelfristigen Zielarchitektur weiter. Derzeit Ausblick, nicht Teil des aktuellen Standes.
AUSBLICKBewusste Grenzen der Offenlegung
Rollen-Konsultation, Bewertungs- und Konsolidierungsmechanismen sind nicht-öffentliche Eigenarbeit. Die Sektion macht die strukturelle Komplexität sichtbar, ohne die Implementierungs-Mechanik offenzulegen.
Wert des Frameworks
Der Wert liegt in der Verbindung von Business-Analyse, Governance, Pattern Intelligence, Solution-Denken, Architekturdenken und Entscheidungsmodell zu einer Sequenz. Diese Verbindung ist nicht trivial nachzubauen.
Die folgenden Schichten sind Beispiele aus einem grösseren Spektrum möglicher Anwendungsfälle. Welche Schichten in einem konkreten Unternehmen relevant werden, hängt von der Reifegrad-Stufe der dortigen Prozesse und der internen Governance-Kultur ab.
Pre-Distribution-Schärfung
BA-, PO- und Process-Owner-Empowerment
Proaktive Eigeninitiative gegenüber dem Sponsor
Budget- und Portfolio-Steuerung
Ressourcen- & Kapazitätsplanung
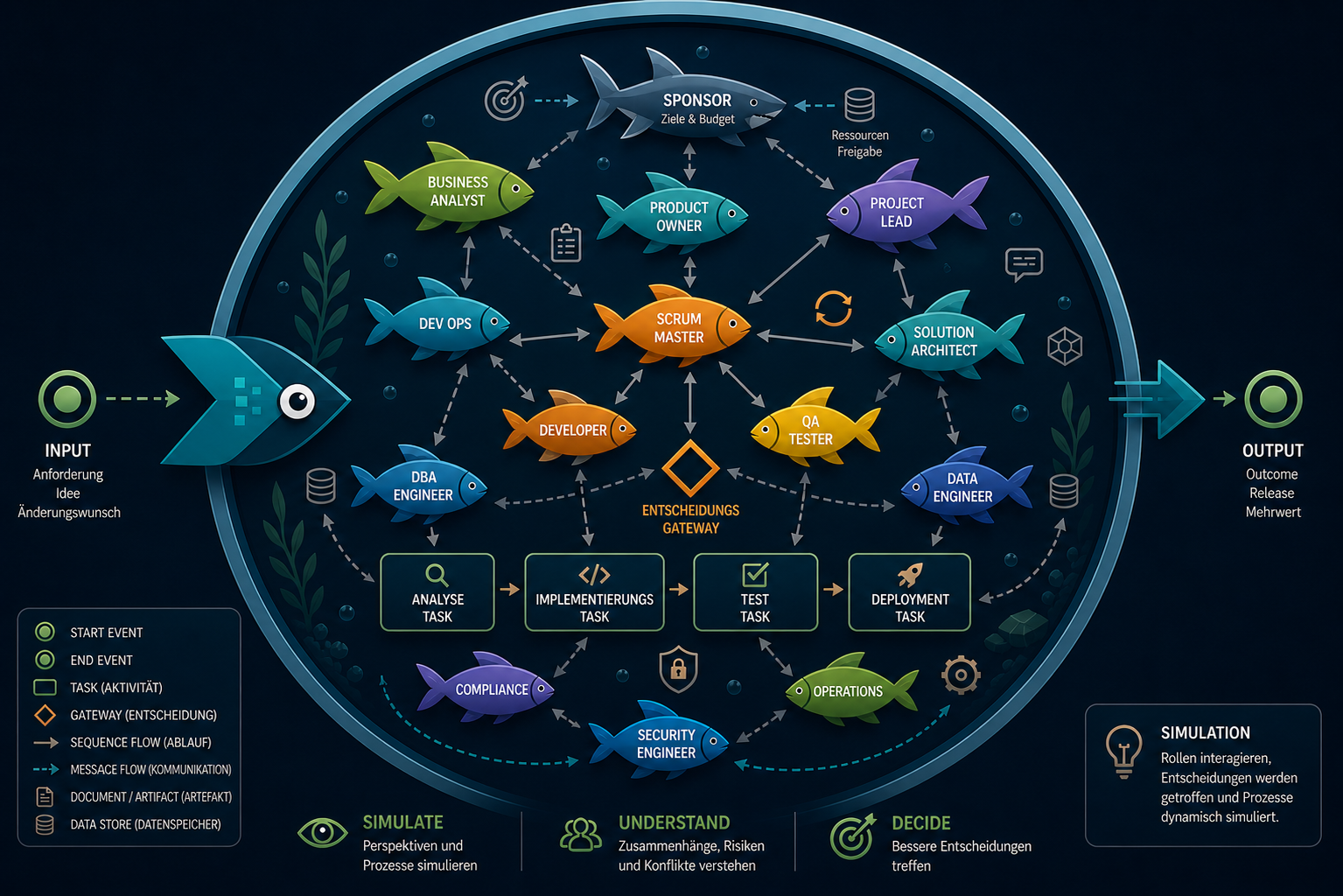
Die rollenbasierte Konsultation arbeitet mit zwei klar getrennten Strukturen. Der Sponsor steht ausserhalb des Schwarms als Mandatsgeber. Der Schwarm besteht aus mehreren Rollen-Gruppen, deren Sichtweisen parallel erhoben und gegeneinander geprüft werden.
Sponsor
Vision · Ressourcen · Mandat · Rückendeckung
Zehn Rollen-Gruppen im Schwarm
Business Analysis
Anforderungen, Akzeptanzkriterien
Product & Strategy
Produktvision, Priorisierung
Engineering & Architecture
Umsetzbarkeit, Architektur
Quality & Testing
Testbarkeit, Qualität
Security & Compliance
Security, Compliance
Operations & Runtime
Betrieb, Monitoring
Process Governance
Prozess, Governance
Delivery & Collaboration
Delivery, Sprintfähigkeit
UX & Experience
Nutzerwert, Bedienbarkeit
AI Governance
KI-Governance, Kontrolle
Die innere Konfiguration der Rollen und die Mechanismen ihrer Konsultation sind Teil der nicht-öffentlichen Eigenarbeit. Diese Sektion macht die Struktur der Konstellation sichtbar, ohne die operative Mechanik offenzulegen.
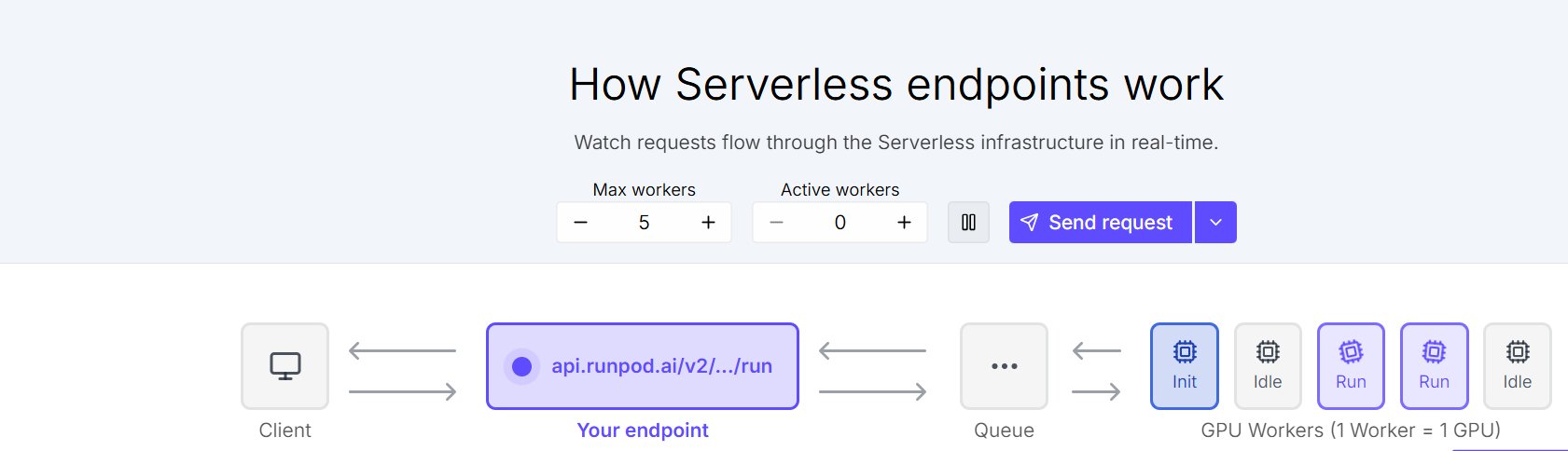
Die Sektion beschreibt, wo das Framework heute läuft, welche Skalierungsstufen vorgesehen sind und wie die Datenhaltung in den verschiedenen Stufen geregelt ist. Die heutige Schicht läuft auf einem Minisforum NAB9 mit Intel-i9-12900HK-Prozessor, 64 GB Arbeitsspeicher und integrierter Grafikeinheit. Auf dem Gerät arbeitet eine Ubuntu-VM unter VMware Workstation, in der ein lokaler Ollama-LLM-Stack betrieben wird.
Wegen der integrierten Grafikeinheit ist die parallele Konsultation virtueller Rollen auf der lokalen Stufe begrenzt. Für umfangreichere Konstellationen wird Hardware mit dedizierter GPU-Leistung benötigt. Das Framework ist deshalb auf drei Skalierungsstufen ausgelegt, die je nach Anwendungs- und Datensensitivität gewählt werden können.

Aktueller Stand. Ressourcenschonend, ohne Cloud-Abhängigkeit, deckt die Demonstrations- und Entwicklungsphase ab. In dieser Stufe verlassen Daten den eigenen Betrieb nicht. Anforderungen, ihre Auswertungen und der Entscheidungsreport bleiben auf dem eigenen Gerät. Für Kontexte mit höheren Anforderungen an die Datenhaltung wäre eine weitere Ausbaustufe denkbar.
Der LLM-Betrieb wird in eine dedizierte GPU-Cloud-Umgebung mit serverlosem Endpunkt verlagert. Die Wahl des Cloud-Standorts erfolgt unter Berücksichtigung der jeweiligen Datenschutzanforderungen, einschliesslich Schweizer Anbietern wie Exoscale, Infomaniak oder SwissAI für Anwendungsfälle mit hohen Souveränitäts-Anforderungen.
Diese Stufe ist als Ausblick angelegt und nicht Teil des aktuellen Standes. Sie ist auf unsensible Anwendungsfälle oder anonymisierte Auswertungen beschränkt und setzt eine interne Freigabe durch die zuständigen Compliance-Funktionen voraus.
Vertiefung pro Stufe
| Host-System | |
|---|---|
| Gerät | NAB9 Venus |
| CPU | i9-12900HK |
| Kerne / Threads | 14 / 20 |
| RAM | 64 GB DDR4 |
| RAM-Aufbau | 2 × 32 GB |
| GPU | Iris Xe, 96 EU |
| Storage | ca. 5,7 TB |
| Host-OS | Win 10 Pro 25H2 |
| Virtualisierung & Gast | |
|---|---|
| Plattform | VMware WS Pro 25 |
| Ziel-VM | DecisionCoreSystem |
| Gast-OS | Ubuntu 24.04 LTS |
| Codename | noble |
| Container | Docker 29.1.3 |
| Verwaltung | Portainer :9000 |
| Runtime & Entwicklung | |
|---|---|
| LLM-Runtime | Ollama 0.23.1 |
| Python | 3.12 |
| Git | 2.43.0 |
| Modell A | qwen2.5:3b | 1,9 GB |
| Modell B | qwen2.5:7b | 4,7 GB |
| Modell-Volumen | ca. 6,6 GB |
| Pod-Konfiguration | |
|---|---|
| Architektur | Serverless Endpoint |
| GPU | 2 × RTX 3090 |
| vCPU | 64 (EPYC 7H12) |
| RAM | 251 GB |
| Skalierung | provider-seitig |
| Abrechnung | pay-per-second |
| Provider-Optionen | |
|---|---|
| International | RunPod, Lambda |
| Schweiz | Exoscale, Infomaniak |
| CH-Spezial | SwissAI |
| Standort | nach Datenschutz |
| Compliance | GDPR / nDSG |
| Vertragsform | pay-per-use |
| Modell & Betrieb | |
|---|---|
| Modellgrösse | 30B bis 70B Q4 |
| Konstellation | alle 16 Agents |
| Kontextfenster | 32k bis 128k Token |
| Datenpfad | Client > Queue > Worker |
| Worker-Lifecycle | idle > Shutdown |
| Image-Basis | Docker, identisch lokal |
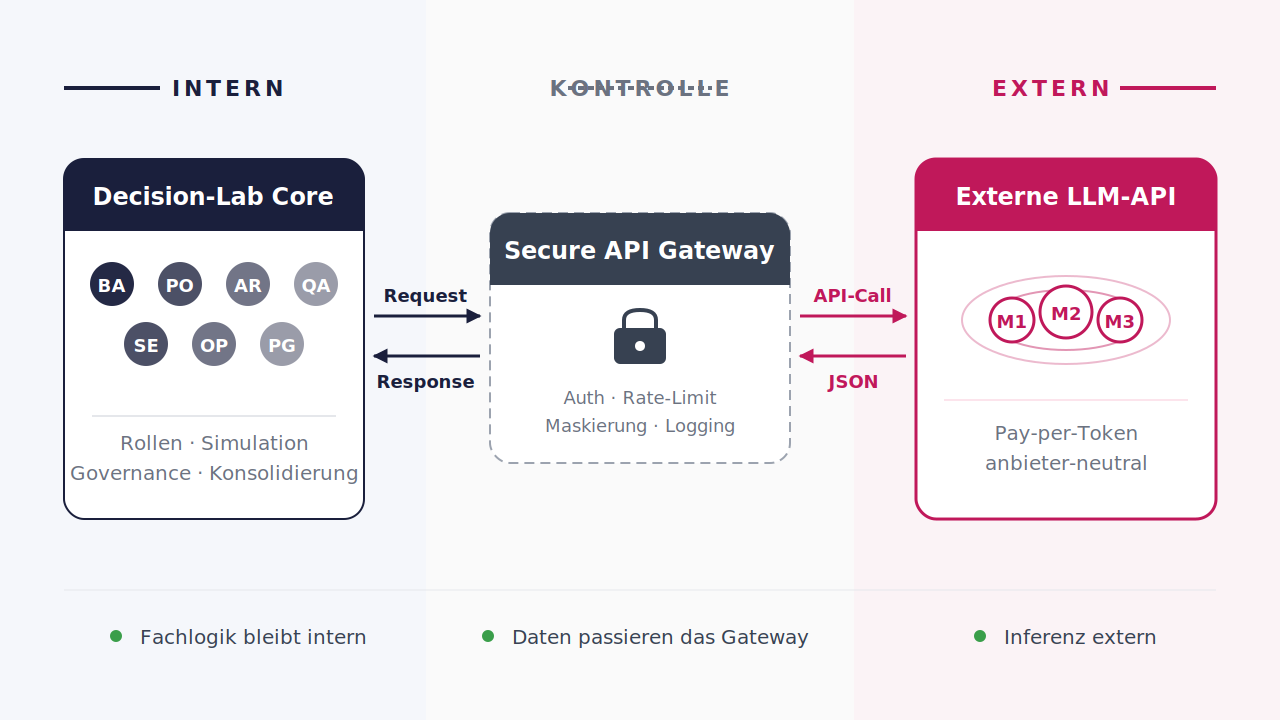
| Technische Spezifikation | |
|---|---|
| Integration | REST / HTTPS |
| Authentisierung | API Key / Service Account / Backend Proxy |
| Datenfluss | kontrolliert, protokolliert |
| Output | strukturierte JSON-Antwort |
| Governance | Policy- und Freigabelogik |
| Kostenmodell | nutzungsabhängig |
| Voraussetzung | Datenschutz und Compliance |
Die hier beschriebenen Architektur-Stufen markieren die heutige Reife und den vorgesehenen Wachstumspfad. Konkrete Konfigurations-Details der LLM-Runtime, der Speicher-Strategie und der internen Kommunikations-Mechanismen sind Teil der nicht-öffentlichen Eigenarbeit.
Die Sektion beschreibt die fachliche Herkunft des Frameworks, den konzeptionellen Bezug zu vorhandenen Open-Source-Arbeiten und die Abgrenzung der eigenständigen Anteile.
Das Framework ist aus 20 Jahren Business-Analyse-Praxis in Banking, Versicherung und Medien gewachsen. Stationen umfassen unter anderem Mandate bei Credit Suisse, BANK-now, ElipsLife (Swiss Re) und Goldbach Media (Tamedia). Die formale Methodengrundlage umfasst die Zertifizierungen IREB Certified Professional for Requirements Engineering und IPMA Level D. Ergänzend wurde der MAS in Business Process Engineering an der FHS St. Gallen abgeschlossen. Wiederkehrende Muster aus diesen Mandaten sind in die rollenbasierte Konsultation und in die Bewertungs-Strukturen eingeflossen.
Der visuelle und konzeptionelle Anker für die Schwarm-Metaphorik ist das Open-Source-Projekt MiroFish, eine Schwarmintelligenz-Engine auf Basis der Frameworks OASIS und CAMEL-AI, veröffentlicht unter der Lizenz AGPL-3.0. Übernommen wurden der konzeptionelle Ansatz der parallelen Konsultation mehrerer virtueller Rollen sowie die Aquarium- und Fisch-Metaphorik in der Visualisierung. Eigenständig entwickelt wurden der gesamte produktive Code, die Spezifikation der Rollen und Rollen-Gruppen, die Konsolidierungs-Logik und die Übertragung auf den Enterprise-Decision-Vorbereitungs-Kontext. Die Lizenz-Pflichten gegenüber MiroFish sind dort relevant, wo Code übernommen wurde, was in der hier beschriebenen Eigenentwicklung nicht der Fall ist.
Der eigentliche Wert des Frameworks liegt nicht in einer einzelnen technischen Komponente, sondern in der Verbindung von Business-Analyse, Governance-Denken, Pattern-Wissen, Solution-Räumen, Architektur-Skizzen und Entscheidungs-Verdichtung zu einer durchgängigen Sequenz. Diese Verbindung ist über Jahre gewachsen, in der Praxis erprobt und durch die domänen-spezifischen Inhalte der Rollen unterlegt. Sie ist in dieser Form nicht trivial nachzubauen.
Die konkreten Inhalte der Rollen-Wissensbasen, die internen Bewertungs- und Konsolidierungs-Algorithmen sowie die Konfiguration der Iterations-Schritte bleiben Teil der nicht-öffentlichen Eigenarbeit. Diese Sektion macht die Herkunft und die Eigenständigkeit sichtbar, ohne die innere Mechanik offenzulegen.
Für ein Gespräch zur Anwendbarkeit im eigenen Unternehmen oder für konkrete Anfragen zu Mandaten und Festanstellungen.